
Utiliser l’IA d’aujourd’hui.
(Source: mooc Coursera “AI For Everyone” Andrew Ng , Stanford University)
L’Intelligence artificielle (IA) est en train de changer notre façon de travailler et de vivre mais pas comme le laisse entendre une certaine mythologie évoquant l’apparition de robots aussi intelligents que l’homme et venant prendre sa place.
Ce dernier aspect de l’IA, qui fait référence à une machine capable de produire un comportement intelligent, voire d’éprouver de « vrais sentiments » et que les experts nomment « Intelligence artificielle forte » (« Artificial General Intelligence » AGI) n’est pas pour les décennies à venir.
Ce qui est à œuvre et prometteur aujourd’hui, c’est ce que les experts appellent «Intelligence artificielle faible » (« Artificial Narrow Intelligence », ANI). Ici, l’intelligence reste exclusivement humaine et utilise les capacités des ordinateurs et de la statistique pour automatiser des tâches, faciliter des processus de décision, etc.
Comme le montre le graphique qu’on trouvera dans l’article de wikipedia https://fr.wikipedia.org/wiki/Intelligence_artificielle#Création_et_développement le contenu réel de l’intelligence artificielle d’aujourd’hui est essentiellement composé de l’apprentissage automatique (« Machine learning », ML) et du réseau de neurones artificiels (« Deep learning » DL)
Dans l’un comme dans l’autre cas, il s’agit de construire un logiciel qui « relie » (corrélation) des données d’entrée (déterminants) à des données de sortie (résultats) et donne automatiquement le résultat désiré.
Ce peut être aussi un logiciel qui « classifie » des données diverses et fournit une segmentation pertinente.
Mais dans tous les cas, c’est l’homme qui définit les données d’entrée et de sorties et qui se sert de la statistique pour obtenir la corrélation ou la segmentation la plus pertinente.
- Définition du « Machine learning »(ML) et du « Deep learning » (DL)
Commençons par mieux définir les 2 types de composants de l’IA d’aujourd’hui
1.1. L’apprentissage automatique ou apprentissage machine ou « Machine Learning » (ML).
On peut vouloir trouver rapidement et automatiquement le prix d’un logement compte tenu de certaines de ces caractéristiques, construire un filtre anti-spam, traduire la parole en texte (reconnaissance vocale) ou obtenir une traduction automatique, donner des ordres à un robot, cibler la publicité selon les caractéristiques d’un prospect, doter une voiture autonome d’un moyen de localiser les autres voitures , reconnaître tel visage ou image, repérer tel défaut de fabrication, repérer telle anomalie dans une radiographie, etc. Ces besoins peuvent être satisfaits grâce au ML.
Mais seul l’homme peut faire, par exemple, les opérations suivantes :
-analyser un marché et rédiger un rapport ;
-faire une réponse adaptée et empathique à un email de client ;
-décoder l’intention d’une personne faisant signe à une voiture autonome ;
-faire le diagnostic d’une maladie à partie d’images d’un chapitre d’un manuel médical.
On voit que le ML ne traite que des taches simples et répétitives alors que la complexité est réservée à l’intelligence humaine.
1.2. L’apprentissage en profondeur ou réseau de neurones ou « Deep learning » (DL).
Ces termes traduisent la même réalité mais la dénomination « Deep learning » est la plus utilisée.
Le DL n’est pas fondamentalement différent du ML mais il prend en compte des relations plus complexes entre déterminants et résultats.
Pour simplifier, on pourrait dire que le ML conduit à construire et utiliser des relations entre 2 ou quelques variables (caractéristiques d’une maison ou d’un produit et prix) alors que le DL construit et utilise des modèles explicatifs complexes comme le montre les 2 schémas suivants :
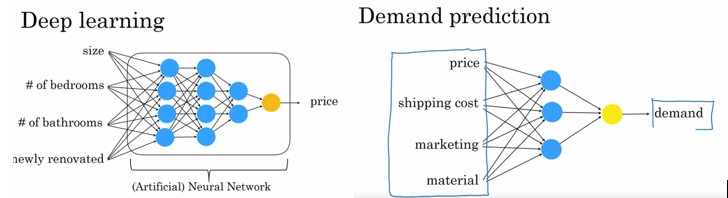
Source: “AI For Everyone” Andrew Ng, Stanford University)
Concernant la maison, on retient 4 types de déterminants et on recherche les effets de leur combinaison sur le prix ; et on procède pareillement concernant la demande d’un produit.
Les « ronds » sont appelés neurones (centres de calculs) et les liaisons statistiques entre variables via les neurones constituent le réseau de neurones, c’est-à-dire en d’autres termes le modèle explicatif du résultat recherché.
Ainsi, dans le schéma ci-dessus, à droite, la demande tend à baisser avec le coût de l’achat (combinaison du prix et du coût de la livraison) mais elle tend à augmenter avec le degré de qualité du produit et l’effort de marketing ; le dernier neurone jaune prend en compte l’ensemble des calculs précédent pour déterminer le résultat.
On imagine facilement que pour la voiture autonome, par exemple, le réseau de neurone doit être infiniment plus complexe.
Dans tous les cas, chaque neurone calcule une fonction simple mais le réseau peut calculer des fonctions très complexes et tous les calculs peuvent être refaits automatiquement et rapidement si on introduit de nouvelles données. C’est en ce sens, que l’on parle de « l’apprentissage » de la machine.
- Construire un projet d’apprentissage automatique.
Définir le plan de réalisation est beaucoup plus simple et facile à faire que de le réaliser.
En simplifiant, on peut repérer trois étapes : la collecte des données, la construction du modèle et la mise en œuvre-validation. Notons d’emblée qu’à chaque étape les tâtonnements, vérifications, itérations sont inévitables.
Concrétisons ce processus via 3 exemples :
2.1. La construction d’un haut-parleur « intelligent ».
Le robot Alexa, par exemple, fournit une réponse à de nombreuses questions (simples) qu’on lui pose, à condition de reconnaître avec certitude qu’on s’adresse à lui, de comprendre ce qu’on lui demande et d’entre capable de fournir la réponse.
On voit les étapes du travail à faire :
-d’abord collecter des données pour lui apprendre à reconnaître qu’on s’adresse à lui. Cette étape va conduire à demander à de nombreuses personnes de dire « Alexa » ou d’autres mots pour leur appel, à enregistrer ces dires, puis à programmer la reconnaissance vocale du « mot déclencheur».
-puis il faut programmer la compréhension de la question ; c’est-à-dire rendre le haut-parleur capable de comprendre la demande et ses variantes, de reconnaître l’intention du demandeur.
-puis il faut établir la liste des réponses possibles à chaque question (liste nécessairement limitée).
-puis il faut construire la relation exclusive entre la question et la réponse.
-enfin, il faut vérifier et valider le ou les logiciel(s) ; l’installer dans un haut-parleur réel et tester son efficacité. On peut alors constater, par exemple, que la diversité des langues ou des accents n’a pas été suffisamment prise en compte et qu’une itération est nécessaire.
On image facilement ce qu’il faudrait faire pour qu’Alexa réponde correctement à une longue série de questions ; ce qui indique les limites inéluctables de l’IA dans ce domaine.
2.2. La construction d’une voiture autonome.
Le fonctionnement d’une voiture autonome implique un ensemble très considérable d’outils d’intelligence artificielle. Considérons à titre d’exemples trois d’entre eux : la détection de la position des voitures situées devant elle, la planification du mouvement et la détection de l’intention du piéton.
2.2.1. Détection de la position des voitures situées devant.
Pour construire la reconnaissance de cette position, il faut collecter des prises de vues (photos ou vidéos) de voiture ou d’autres engins roulants, de dos, situées sur le même côté de la route ou en cours de doublement ainsi que des photos de ce qui n’est pas une voiture située devant (arbre, etc.). On doit vérifier, bien sûr, que la reconnaissance est sûre et que des types d’engins roulants n’ont pas été oubliés. Ceci peut être aussi fait pour détecter un piéton ou un autre obstacle. Plus généralement, aujourd’hui, sont installées des caméras orientées vers la gauche, vers la droite et vers l’arrière et des capteurs divers afin de détecter les voitures non seulement situées devant mais tout autour.
2.2.2. Planification du mouvement
Le logiciel de planification de mouvement doit indiquer le chemin à parcourir ainsi que la vitesse à respecter pour ne heurter rien ni personne et respecter le code la route.
Cela implique de mesurer la distance séparant la voiture d’un obstacle ainsi qu’une prédiction de la trajectoire de l’obstacle ; de traduire les changements de direction en angles de braquage pour le volant, de définir les commandes d’accélération, de freinage, de dépassement, etc. ; enfin, de savoir où se trouvent les voies et de détecter les marques de voie, les feux de signalisation, etc.
2.2.3. Détection de l’intention du piéton ou du cycliste.
C’est sans doute une des questions les plus difficiles car l’intention est nécessairement perçue via l’image (photo ou vidéo) d’un geste. Or le nombre de façons dont les gens pourraient faire signe à une voiture est très grand et, souvent, le signe fait est difficile à comprendre pour un conducteur de voiture d’aujourd’hui. C’est pourquoi, aujourd’hui, la détection des autres voitures progressent et pas celle de l’intention des piétons, etc.
2.3. L’optimisation d’une ligne de fabrication.
Imaginons que cette ligne fabrique des tasses à café (ce qui implique de façonner et vernir, passer au four puis inspecter, etc.) et que l’objectif soit de réduire au maximum les malformations et défauts divers.
La collecte des données, ici, conduit à enregistrer les déterminants connus du succès (qualité de l’argile, humidité, température et durée de cuisson, etc.) ainsi que le résultat final ; et le modèle d’apprentissage machine devra relier déterminants et résultats.
La mise en œuvre devrait permettre de surveiller et réguler les déterminants au vu des résultats ; éventuellement de collecter à nouveau des données pour perfectionner le modèle.
Cette surveillance peut être faite de visu mais se trouve beaucoup facilitée par une inspection vidéo des résultats et le rassemblement de tous les indicateurs de déterminants sur un unique écran (Internet des objets). Ce qui est de nature à faciliter et rendre plus performants les responsables de chaîne de fabrication.
- Conseils d’un expert international au dirigeant débutant en IA.
Andrew Ng, ancien directeur chez Google Brain et chez Baidu, est professeur à la Stanford University et créateur du site : https://landing.ai/ai-transformation-playbook/
Voici ses 3 conseils principaux :
3.1. Sélectionner le(s) premier(s) projet(s) d’IA.
On peut, ici, retenir les principes de choix suivants :
-ce sont les tâches et non les emplois qu’on cherche à automatiser ;
-il vaut mieux choisir de renforcer le(s) service(s) point(s) forts de l’entreprise ;
-il faut vérifier la faisabilité et la pertinence du ou des projets d’IA retenus car tout projet prend du temps mais peut être ni réalisable, ni « rentable » pour l’entreprise, ni socialement acceptable, etc.
On a donné ci-dessus un exemple d’optimisation d’une ligne de fabrication.
Voici quelques suggestions concernant d’autres services.
Pour les vendeurs, on pourrait imaginer faciliter et optimiser leur travail en les aidant à hiérarchiser les prospects à démarcher sur des bases plus solides que l’intuition. La collecte de ce qui a déterminé les anciens prospects à devenir clients ou à rester prospect peut être le modèle prédictif nécessaire et régulièrement actualisé.
Pour les recruteurs, une application d’analyse de texte et une sélection de mot clés peuvent assurer le filtrage automatique des CV et la sélection des candidats avec qui établir un contact plus approfondi.
Pour les marketeurs, et à l’instar de ceux d’Amazon, leur donner le moyen de proposer aux clients ou visiteurs des produits à acheter, sélectionnés sur la base de ce que qu’ils savent de ces clients et visiteurs.
3.2 Etapes à respecter.
3.2.1. Commencer par un projet pilote initial choisi principalement pour sa rapide faisabilité.
Il s’agit ici d’apprendre, d’obtenir des résultats et par suite de démontrer l’importance de l’IA dans l’entreprise. Il est recommandé d’externaliser le choix comme la réalisation du projet pour bénéficier de l’expérience d’un prestataire professionnel.
3.2.2. Constituer une équipe interne d’IA, rattachée à la direction générale et lu donner les trois objectifs suivants :
-définir et commencer d’acquérir les outils logiciels et techniques nécessaires à l’ensemble de l’entreprise ; -définir un plan de formation à l’IA des cadres ;
-se mettre au service d’un département choisi de l’entreprise.
Ici aussi le recours à l’externalisation peut être une bonne solution initiale.
3.2.3. Elaborer une stratégie d’intelligence artificielle.
Il est bon que cette étape ne soit entreprise qu’à ce stade car cette élaboration exige de l’expérience en IA et la présence de quelques compétences. On notera, ici, les points importants suivants :
-l’objectif n’est pas d’imiter les applications connues mais de créer une intelligence artificielle spécialisée pour l’entreprise ;
-la réflexion doit porter sur les moyens d’obtenir le maximum des données nécessaires (en pratiquant une forme de gratuité, etc.) et sur un stockage de ces données qui facilite leur utilisation.
3.3. Outils de ML et DL gratuits disponibles :
-Outils de ML et DL open source : TensorFlow – PyTorch – Keras – MXNet – CNTK- Caffe, etc.
-Publications disponibles gratuitement sur le site Arxiv.
NB : On trouvera dans l’article https://outilspourdiriger.fr/les-applications-cognitives-1/ d’utiles compléments sur le ML et sur les grands prestataires de services dans ce domaine.
Aucune reproduction ne peut être faite de cet article sans l’autorisation expresse de l’auteur ». A. Uzan. 7/10/2019