
Trois types d’analyse des données nécessaires aux managers concerne trois types de problèmes fréquemment rencontrés par les managers et dont chacun nécessite une analyse de données particulière.
Il est maintenant généralement admis que les décisions doivent se prendre sur la base de l’analyse des données et non de l’intuition, laquelle peut, cependant, suggérer les hypothèses à vérifier.
On présentera : repérer les « clusters », repérer les facteurs d’un résultat et prévoir.
- Repérer des « clusters » (groupes homogènes).
Voici trois situations qui nécessite le repérage de clusters pour agir de façon plus ajustée.
-Le responsable d’une « supply chain » juge nécessaire de réorganiser la gestion des stocks mais il se rend compte que les données globales qu’il produit ne lui permettent pas de segmenter les produits et donc de définir des politiques différenciées plus adaptées qu’une politique globale.
-Le directeur RH voudrait comprendre les raisons du départ de nombre de ses collaborateurs pour agir de façon plus ajustée.
-Le directeur commercial d’une entreprise de Télécoms a l’intuition que sa politique commerciale est trop globale et qu’il faudrait l’ajuster au type de client.
On a compris que, généralement, les « objets » à manager (stocks, collaborateurs, clients, etc.) donnent lieu à des données statistiques globales hétérogènes ne permettant pas de décider du traitement différencié nécessaire.
La méthode du « clustering » est une sorte de segmentation ou de typologie opérée par un logiciel. Elle vise à organiser des données brutes en silos homogènes, à faire que les membres de chaque groupe soient les plus semblables et les groupes soient les plus dissemblables les uns des autres.
L’objectif est de traiter les groupes de façon différenciée, « personnalisée ».
On ne présentera pas les logiciels opérant ce clustering (l’auteur du Mooc utilise le logiciel R), ce qui relève du « Data Analyst » mais la préparation, l’interprétation, la présentation des résultats et la décision qui relève du manager.
1.1. La gestion des stocks
On sait que la variabilité de la demande des produits stockés oblige à rechercher une optimisation.
Une solution intuitive pourrait conduire à la segmentation suivante :
-les produits 1 dont les ventes sont élevées et dont la variabilité est faible ;
-les produits 2 dont les ventes sont élevées et la variabilité grande ;
-les autres produits, 3.
On peut ainsi gérer de façon ajustée :
-les demandes de produits 1 sont prévisibles et importantes, on peut avoir un stock important même coûteux ;
-les produits 3 peuvent être fabriqués à la commande ;
-Les produits 2 doivent être gérés au cas pour cas.
On peut appliquer une approche plus rigoureuse pour créer des groupes par le « clustering hiérarchique ».
Voici ce que donne cette méthode :
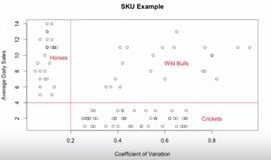
On retrouve les mêmes groupes que ci-dessus mais maintenant avec une approche plus rigoureuse et pouvant repérer des groupes dans des masses importantes de données.
On veillera cependant à limiter le nombre de groupes (3 par ex.) selon des critères commerciaux pour pouvoir les traiter.
1.2. Les départs de l’entreprise.
Le directeur RH voudrait comprendre les raisons du départ de nombre de ses collaborateurs pour ajuster sons action.
Il dispose de données collectées lors des entretiens de départ : satisfaction de l’employé à l’égard de l’entreprise (S) la dernière évaluation (LPE), le nombre de projets achevés au cours des 12 derniers mois (NP), le nombre moyen d’heures travaillées par mois (ANH) le temps passé dans l’entreprise (TIC) et s’il a eu un bébé au cours de l’année écoulée (Newborn), donnés figurant dans le tableau ci-dessous ;
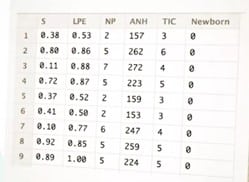
Le premier travail du Data Anayst est de rendre ces variables comparables en les normalisant.
Par ailleurs le DRH décide d’avoir 4 segments maximum.
Voici les résultats :

-Le segment 1, « Low Perf » est composé de collaborateurs ayant peu d’ancienneté, qui ont réalisé peu de projets en moyenne et qui ont été sous-utilisés.
-Le segment 2 « High Potential » est composé de collaborateurs qui travaillent le plus, qui ont de bonnes évaluations mais qui sont moins satisfaits.
-Le segment 3, est composé de collaborateurs qui sont dans l’entreprise depuis longtemps, ont réalisé beaucoup de projets mais présentent un faible niveau de satisfaction,
-Enfin, le dernier segment ne présente aucune caractéristique distinctive. Appelons-le le segment « Divers ».
Les conclusions principales sont alors simples.
-ne rien faire pour retenir les collaborateurs à faible performance ;
-faire quelque chose rapidement pour les « déçus »
-retenir les hauts potentiels bien que cela soit difficile
1.3. Les clients de l’entreprise de Télécoms
Pour chaque client, on dispose des informations suivantes : durée moyenne des appels nationaux par mois, temps passé à des appels internationaux, nombre de SMS envoyés et âge du client.
Si on aplique la méthode comme si dessus ; on trouve les résulyays suivants :
-un segment d’utilisateurs professionnels qui fait beaucoup appels nationaux et internationaux mais moins de SMS ;
-un segment d’utilisateurs qui passe de nombreux appels, utilise beaucoup de données et de SMS ;
-un segment de jeunes adultes utilisant beaucoup de données et de SMS, mais moins d’appels ;
-un segment de personnes plus âgées « Silver » qui ont une faible utilisation globale, mais sont plus aguerri.
– un segment d’utilisateurs léger.
Il est clair que, dans chacun des cas, le clustering a amélioré la connaissance des « objets » et surtout permis des actions plus ajustées. Mais il faut réunir les conditions du succès : des données nombreuses et pertinentes, une lecture des résultats du clustering permettant la décision et l’action.
- Repérer les facteurs d’un résultat.
Voici deux situations qui nécessite ce repérage ;
-Un banquier veut évaluer les notes de crédit attribuées à ses clients en recherchant les facteurs les plus importants de cette notation.
-Le directeur RH voudrait une deuxième analyse pour repérer les facteurs du départ des collaborateurs
Dans ces deux cas, c’est la régression linéaire (ou logistique), qui va servir d’outil de base
Notons tout de suite que la corrélation n’indique pas la causalité et que souvent, les données corrélées sont la conséquence de la même cause.
2.1. Evaluation de la note de crédit
C’est une évaluation du risque que représente un client pour un banquier et un des critères de l’attribution du crédit.
Imaginons que cette note a été attribuée à 300 clients et que nous connaissons, pour chacun, le revenu annuel, le nombre de cartes de crédit possédées, l’âge, le niveau d’éducation, s’il est étudiant, s’il est marié, son origine ethnique, la dette moyenne par carte de crédit détenue.
On peut pratiquer une régression multiple entre ces données et la notation et tester la validité de la régression en corrélant un échantillon des données avec les résultats réels qui n’ont pas été utilisés pour estimer les paramètres du modèle (données témoins).
Si la dernière corrélation est forte on peut rechercher les facteurs significatifs le plus importants fournis par le logiciel.
Voici les données et les facteurs le plus importants = ***
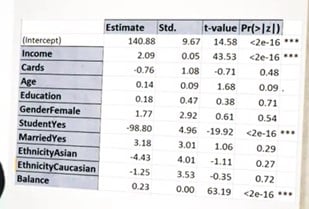
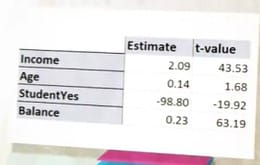
Examinons donc la valeur absolue de la colonne T-value et les facteurs les plus importants (=***)
On voit que ces facteurs sont, dans l’ordre décroissant : la dette par carte de crédit, puis le revenu, puis le statut d’étudiant. L’âge est peu significatif et le statut d’étudiant est un facteur négatif.
2.2. Le départ des collaborateurs
On sait que les deux effets les plus importants du départ sont la satisfaction et le nombre d’années écoulées depuis l’arrivée dans l’entreprise. Les effets importants connus, on peut simplement utiliser une méthode graphique, en croisant le temps passé dans l’entreprise et le taux moyen de départ

- Prévoir.
La capacité de prévoir ce qui est susceptible de se produire et à quel moment est probablement l’une des questions les plus importantes pour un manager.
3.1. Les outils classiques
Ce sont la régression (ajustement d’une droite ou d’une courbe) et la corrélation.
Les ajustements s’appliquent surtout aux séries chronologiques. On peut ainsi repérer la tendance d’évolution et dresser des scénarios sur son évolution future.
La prévision est facilitée si on peut établir une corrélation pertinente entre la série chronologique observée et une autre série plus facile à prévoir (tendance à prendre appui sur des statistiques de population ou des statistiques publiques). On n’oubliera jamais, alors, que la corrélation peut signaler une covariation sous l’effet d’une cause commune et non une relation de cause à effet.
3.2. Les prévisions relatives à certains clusters
Une fois fait le clustering, on peut se concentrer uniquement sur les segments qui posent un problème.
Par exemple, concernant le problème de l’évaluation de la note crédit, on pourrait se concentrer sur la prévision de la population qui n’a pas encore de note ou se concentrer sur toute la population qui n’a pas de mauvaise note.
Autre exemple, sur la base du travail fait sur le départ des collaborateurs, un logiciel peut déterminer la probabilité du départ de chaque collaborateur et si on croise cette probabilité de départ avec la qualité de la performance on peut définir trois champs d’action, comme indiqué dans le tableau ci-dessous :
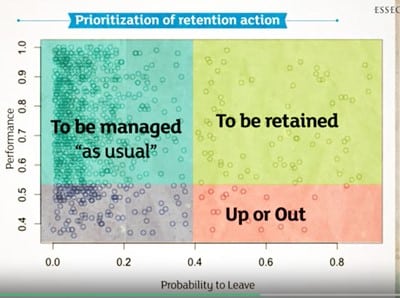
On pourrait appliquer une modèle probabiliste semblable aux achats de produits.
3.3 Les prévisions de saisonnalité.
Beaucoup d’activité sont saisonnières et les managers doivent prévoir cette saisonnalité pour éviter les « invendus » ou la sous-estimation de la demande.
Une méthode simple consiste à ajuster une droite ou une courbe dans les données saisonnières et à calculer des coefficients saisonniers moyens par rapport à l’ajustement.
On peut aussi utiliser un modèle de prévision complète : faire une régression multiple et repérer les facteurs importants, comme indiqué dans le tableau suivant
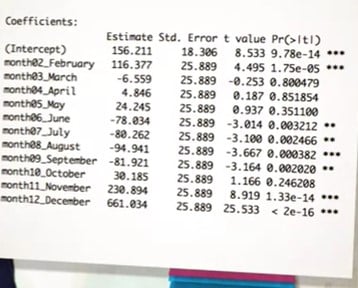
De nombreux mois ont un effet très fort sur les ventes (***) : février ; août, novembre et décembre ont en moyenne un effet positif sur les ventes
C’est surement ce qu’aurait montré un graphique ; et si on avait comparé les valeurs issues du modèle avec les valeurs observées on constate que l’ajustement est très bon.
L’objectif de cet article n’est pas de transformer tout manager en statisticien mais d’alerter le manager sur ce qu’il peut demander au statisticien de faire et ce qu’il peut attendre de ce travail.
((Source : https://www.coursera.org/learn/marketing-management-two/home/week/1)
Pour aller plus loin :
https://outilspourdiriger.fr/avoir-cuture-du-client-et-celle-de-lanalyse-des-donnees/
https://outilspourdiriger.fr/la-segmentaion-rfm-outil-de-prevision/
https://outilspourdiriger.fr/segmenter-cibler-positionner/
Aucune reproduction ne peut être faite de cet article sans l’autorisation expresse de l’auteur. A. Uzan. 23/06/2024